Most IT systems process various data items and the values of these data items influence the results of processing. When we want to test combinations of values of data items, the data combination test (DCoT) is a very useful technique. Especially because this technique may achieve various levels of coverage so it can cater for coverage in cases of low, medium or high-quality risk levels.
| Approach | Coverage based - Data |
|---|---|
| Test variety |
Primarily functionality, also applicable in other test varieties |
| Test basis |
Almost all kinds |
Within functionalities single data attributes and their equivalence classes (see test design technique equivalence partitioning) may influence the system behaviour, but many times combinations of data attributes are of influence on variations in the system behaviour.
Description
The data combination test (DCoT) is a versatile technique for the testing of functionality both at detail level and at overall system level. In the embedded world, this technique is also known as the "Classification Tree Method". It was developed by Grochtmann and Grimm, and is described in "Testing Embedded Software" [Broekman, 2003] and elsewhere.
For the DCoT, no specific test basis is required. All types of information on the functionality of the system are usable:
- Formal system documentation, such as functional design, logical data model and requirements
- Informal documentation, such as manuals, folders, pre-surveys and memos
- Domain expertise that is not documented, but resides 'in the experts' heads'.
The fact that domain expertise is usable as a test basis also makes this technique suitable for situations in which specifications are incomplete or out of date, or even unavailable altogether.
Because of the strongly informal character of this technique, the quality of the test cases designed with it is largely determined by the expertise and skill of those involved. For that reason, the DCoT is preferably carried out by a team of 2 to 5 persons with a mix of expertise: test, domain and system expertise.
To use this test design technique, follow these steps:
- Determine the desired coverage level
- Determine the relevant data items
- Determine the equivalence classes for each data item
- Determine dependencies between data items
- Draw a classification tree
- Use the classification tree to combine equivalence classes of the data items into test cases, based on the desired coverage level.
Coverage level
The test strategy usually defines the desired coverage level (for example based on the quality risk level). The DCoT has different levels of coverage that can be achieved; it is good to know beforehand which coverage level is desired.
- The lowest level of coverage is where every different class for each data item is used in at least one test case.
- The highest level of coverage is where all combinations of all classes for each of the data items has been used in a test case.
- In between, the level of coverage called pairwise testing will test each pair of data items (see below for more explanation).
TipOrganise a 'creative session', such as brainstorming or meta-planning, in which the tester acts as moderator of the process. Invite one expert to this session from every relevant discipline, e.g. a user, an administrator and a system developer or system architect. The experts will supply the substantive information, which can be structured by the tester and converted into test situations and test cases. |
With the DCoT, the test situations are determined by reasoning from within the data attribute as to which variations should be tested. The basic technique used here:
Depending on the agreed depth of the test, the coverage can be extended by fully combining the equivalence classes of two or more different data. In this, the following basic techniques can be used:
- Pairwise testing
- Complete decision table (multiple condition coverage) on selected data attributes.
Besides these, there is the option of reinforcing the test by applying boundary value analysis. This can also be applied selectively, by defining the boundary values for specific data attributes as a separate equivalence class.
Thanks to its versatility, the data combination test is suitable both for testing those functions that are deemed very important, and for testing system parts that 'just need a quick test'.
Points of focus in the steps
In this section, the data combination test is explained step by step. In this, the generic steps ("Introduction") are taken as a starting point. An example is also set out, showing at each step how this technique works.
ExampleThis example concerns a function for creating flight reservations: The function should be tested to average depth using the DCoT. |
Identifying test situations is the creative step in the process and is ideally carried out by a team in which various forms of expertise are represented. During this step, the following activities are carried out
Determine relevant data items
From the test basis we determine the data items that are input for (part of) the process that is being tested.
This does not automatically mean all the data attributes that are used by the function. It concerns the data attributes that are of influence on variations in the system behaviour. This includes the data attributes for which equivalence classes can be determined. The defined data can consist of entities, attributes or functional concepts in a general sense.
Determine equivalence classes per data item
See"Equivalence partitioning" for this.
Determine dependencies between data items
Some data attributes are only of influence on the system behaviour under certain conditions, namely if another data attribute has a value from a specific equivalence class. That means that the possible variations of the first-mentioned data attribute must be combined with the specific value of the last-mentioned data attribute. In the example set out, such a relationship is visible between the data attributes "search criterion" and "flies to that destination".
Also, these dependencies may mean that for some logical test cases it would not be possible to create a physical test case because the combination of values cannot be entered in the system.
Drawing a classification tree
- Data attributes that logically belong together can be grouped under an overall title, such as "personal details" or "employer types"
- Under every data attribute the equivalence classes are hung, like branches on the tree.
- Relationships between the data can be shown simply by hanging the relevant parts of the classification tree directly under the relevant equivalence class.
The creation of the classification tree with which the test situations are identified is an iterative and interactive process, in which the parties involved inspire, correct and complement each other. How far this process will go is the choice and responsibility of the team.
If required, it is defined which data attributes are eligible for 'fully combined testing'. That means that all the possible combinations of all the equivalence classes of those data attributes should be tested. How many of such combinations can be defined depends on the agreed depth of testing.
TipThe following can serve as a guideline: |
|
| Elementary | None, or only one data pair. |
| Average | Two or more data pairs. This offers a scale of increasing depth of testing that ends with "pairwise testing". |
| Thorough | Average depth + boundary value analysis. |
|
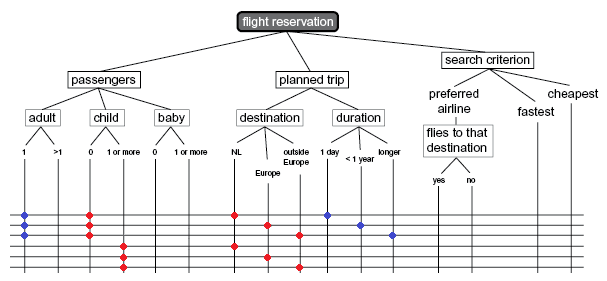
Instead of combinations of two data (data pair), it can also be defined that all the combinations of three data (data triplet) should be tested. This should be treated as an increase in the depth category. In the example the following pairs have been made (depicted in a Classification tree):
|
ExampleFor the function of "flight reservation", the team has worked out the classification tree in the figure below 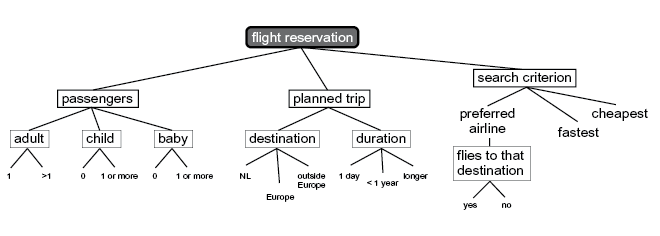
In this, the following aspects, among others, are important:
Two data pairs have been defined, fitting the agreed average depth of testing, which should be tested in total combination:
|
Combine equivalence classes to test cases
With a logical test case, precisely one of the equivalence classes is covered for each data attribute in the classification tree. Collectively, the logical test cases should at any rate cover all the equivalence classes of all the data attributes. Depending on the chosen depth of testing, they should also cover all the combinations of equivalence classes of particular data attributes, if necessary.
Different coverage levels
Please note that the number of test cases grows very rapidly when combining all classes of all data items. If in a specific situation, there are five data items with three classes each, which would mean 3 × 3 × 3 × 3 ×3 = 243 test cases. If there is very high quality-risk level, testing all these test cases may be worthwhile. The team will often want a lower number of test cases, however.
Combining the most relevant data items
In most cases not all data items are equally important to determine the result. The tester can then choose to make all combinations of the relevant data items. For the other data items, they will make sure that at least every different class has been used in a test case. This is a mix of using the highest coverage and the lowest coverage.
Pairwise testing or n-wise testing
This method is usually employed where the "pairwise testing" option has been adopted (see "Orthogonal arrays and pairwise testing" ). Tools for pairwise testing normally deliver their results directly in table form.
Graphic depiction of a 'classification tree'
This is particularly useful if the most elementary form of testing (without combinations) has been chosen, or for the selective application of "complete decision table" coverage. Ideally, a graphic tool should be used here. E.g. "Classification Tree Editor", which was specially developed for this purpose by DaimlerChrysler.
ExampleThe logical test cases are shown with the aid of the classification tree, see the figure below. 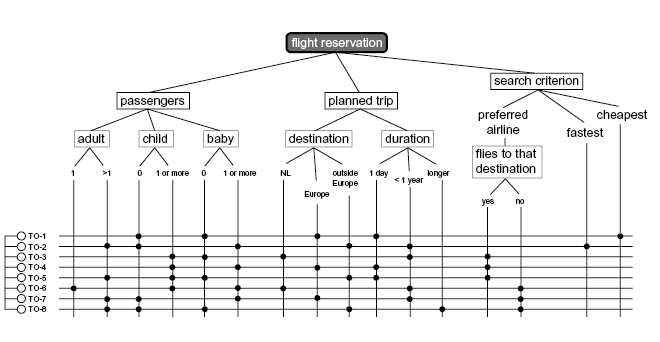
Allowance is made here for the two data pairs that are to be tested in full combination. Test cases TC1 to TC4 incl. cover the data pair "Child – Baby", while the data pair "Destination – Flies to destination" is covered by the test cases TC3 to TC8 incl. N.B. To obtain the minimum coverage, in which all the equivalence classes are solely covered without combinations of data pairs, 4 logical test cases are sufficient here, e.g. TC1, TC2, TC3 and TC8. |
In creating the physical test cases, concrete values should be chosen for all the input data. These input data do not always correspond exactly with the concepts maintained in the classification tree. For example, the classification tree may contain the concept of "duration", while the function to be tested expects the data "Start date" and "End date".
Every physical test case should have a concrete predicted result. However, this generally depends on the other data and system settings that belong with the chosen starting point.
ExampleIn order to illustrate the principle, 4 test cases are made physical in the figure below. With every test case, the physical values are defined for all the necessary input data and the predicted result is described in concrete terms.
|
In order to predict the results of every physical test case, it is necessary to know exactly which flights and prices are stored in the database. This step goes hand-in hand with the next step, "Establishing the starting point".
ExampleThe following database has to be loaded:"TST_RES_03". This contains in particular the situation that the company "Senegal Airlines" exists, but does not recognise "Eindhoven Airport" as a destination. |
An overview of all featured Test Design Techniques can be found here.